TL;DR Replace the standard \(\mathcal{N}(\mathbf{0}, \mathbf{I})\) source with a temporally grounded prior anchored on the agent's recent action history. The flow path becomes shorter and straighter, recovering the path-straightening benefit of OT couplings without any OT solver.
Generative policies based on diffusion and flow matching have become a dominant paradigm for visuomotor robotic control, capturing complex, multimodal action distributions by iteratively transforming samples drawn from a Gaussian prior. In this work, we introduce WarmPrior, a new source distribution for generative policies. Our key idea is simple: rather than a zero-mean prior, we center the Gaussian on the action sequence predicted at the previous inference step. This yields straighter flow trajectories, mirroring the effect of OT couplings in Rectified Flow. Across simulation benchmarks (Robomimic and MimicGen with a Diffusion Policy backbone) and on a real Franka arm with the GR00T N1.5 vision-language-action model, WarmPrior consistently improves success rates. Our results identify the source distribution as an important yet underexplored design axis in generative robot policies.
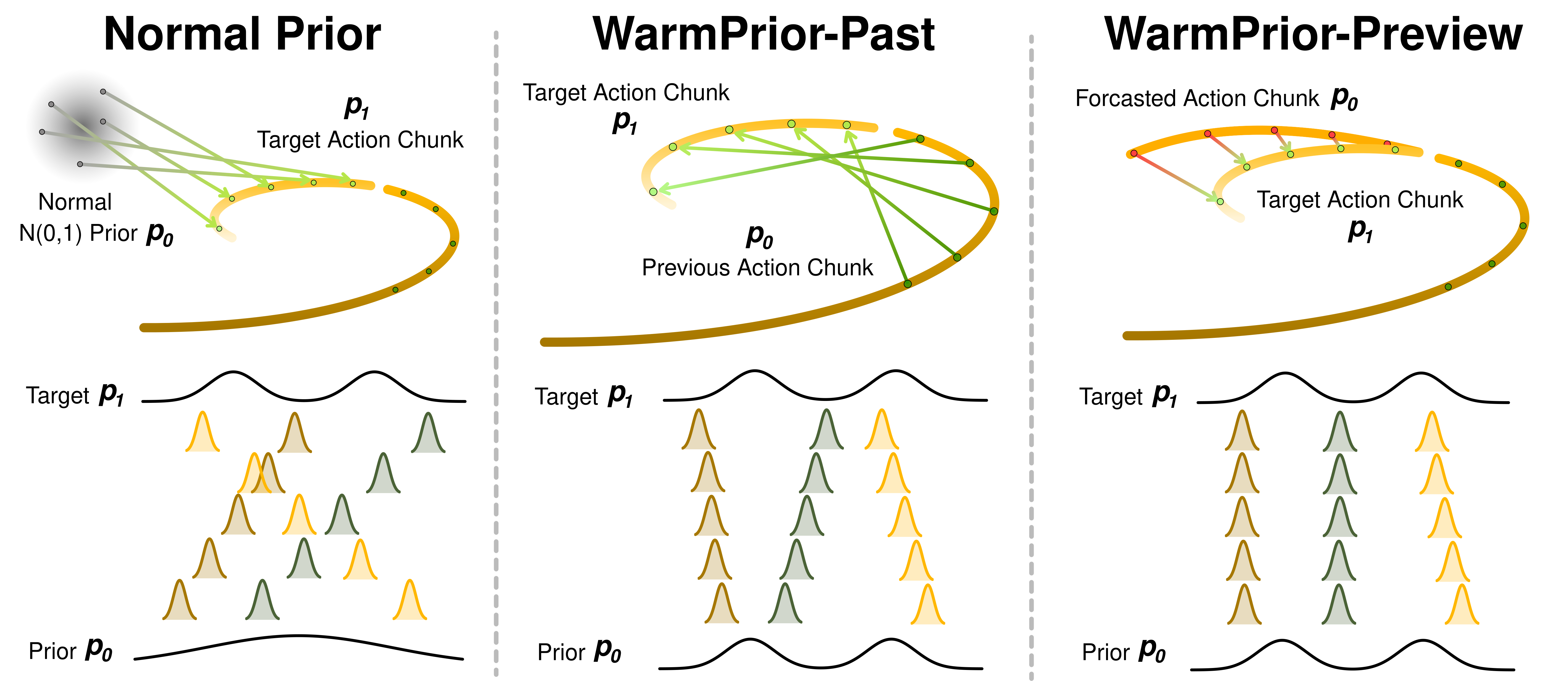
WarmPrior modifies only the source distribution. The network, interpolant, and training objective are untouched. We instantiate it in two minimal variants that differ in how the prior mean is anchored to the agent's own action history.
Use the previously executed action chunk as the prior mean. Consecutive chunks tend to be similar, so the flow starts close to the target.
Predicts \(H\) actions per step.
Predict \(2H\) actions, execute only the first \(H\), and keep the second \(H\) as a preview of the next chunk. At the next decision step, that preview becomes the prior mean.
Predicts \(2H\), executes first \(H\).
Success rate (%) with the Diffusion Policy (ChiTransformer) backbone.
Parentheses: gain over \(\mathcal{N}(\mathbf{0}, \mathbf{I})\).
(Green: non-overlapping 1σ seed intervals.
Bold: best per (task, NFE).)
| Task | NFE = 9 | NFE = 3 | NFE = 1 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Base | WP-Past | WP-Preview | Base | WP-Past | WP-Preview | Base | WP-Past | WP-Preview | |
| Robomimic — state observation | |||||||||
| Square-PH | 86.7 | 88.1(+1.4) | 88.1(+1.4) | 86.2 | 88.0(+1.8) | 87.9(+1.7) | 83.6 | 86.6(+3.0) | 87.3(+3.7) |
| Square-MH | 65.9 | 69.2(+3.3) | 72.7(+6.8) | 65.4 | 73.2(+7.8) | 72.9(+7.5) | 65.9 | 70.1(+4.2) | 77.8(+11.9) |
| Transport-PH | 34.1 | 36.2(+2.1) | 43.3(+9.2) | 39.0 | 44.0(+5.0) | 49.1(+10.1) | 36.8 | 39.8(+3.0) | 47.6(+10.8) |
| Transport-MH | 16.3 | 20.7(+4.4) | 24.3(+8.0) | 21.3 | 30.7(+9.4) | 30.4(+9.1) | 23.3 | 30.2(+6.9) | 34.5(+11.2) |
| Tool-Hang-PH | 79.4 | 80.6(+1.2) | 82.8(+3.4) | 72.3 | 75.1(+2.8) | 75.8(+3.5) | 77.7 | 78.2(+0.5) | 81.9(+4.2) |
| Robomimic — image observation | |||||||||
| Square-PH | 86.9 | 88.2(+1.3) | 88.7(+1.7) | 87.7 | 89.2(+1.4) | 89.6(+1.9) | 88.7 | 89.3(+0.6) | 89.1(+0.4) |
| Square-MH | 76.1 | 78.0(+1.9) | 77.8(+1.7) | 73.8 | 77.9(+4.1) | 77.1(+3.2) | 72.4 | 77.6(+5.2) | 75.1(+2.7) |
| Transport-PH | 92.8 | 94.5(+1.7) | 94.3(+1.6) | 92.1 | 93.9(+1.9) | 94.9(+2.9) | 91.3 | 93.4(+2.2) | 93.7(+2.4) |
| Transport-MH | 74.8 | 79.7(+4.9) | 79.8(+4.9) | 73.8 | 80.0(+6.2) | 80.7(+6.9) | 74.3 | 78.6(+4.3) | 79.7(+5.4) |
| Tool-Hang-PH | 43.7 | 45.8(+2.1) | 56.3(+12.6) | 36.9 | 38.4(+1.4) | 50.7(+13.8) | 41.3 | 38.9(−2.4) | 54.0(+12.7) |
| MimicGen — image observation | |||||||||
| Stack | 21.4 | 22.8(+1.4) | 31.6(+10.2) | 21.3 | 23.7(+2.4) | 30.7(+9.4) | 21.3 | 22.4(+1.1) | 28.7(+7.4) |
| Coffee | 26.8 | 29.6(+2.8) | 34.7(+7.9) | 23.3 | 24.1(+0.8) | 33.4(+10.1) | 16.2 | 20.4(+4.2) | 29.4(+13.2) |
| Threading | 13.8 | 15.5(+1.7) | 20.9(+7.1) | 16.3 | 16.6(+0.3) | 22.0(+5.7) | 12.5 | 15.6(+3.1) | 18.0(+5.5) |
The baseline paths curve noticeably as the network pulls samples from a random origin onto the action manifold; WarmPrior paths, already starting close to the manifold, are visibly straighter and more parallel. Because fewer flows cross one another, the network spends less capacity realigning samples from the random base distribution and can devote more to refining actions, exactly where it matters for downstream success rate.
| Task | N(0, I) | WP-Past | WP-Preview |
|---|---|---|---|
| Square-PH | 1.000 | 0.823 | 0.803 |
| Square-MH | 1.000 | 0.705 | 0.559 |
| Transport-PH | 1.000 | 0.720 | 0.692 |
| Transport-MH | 1.000 | 0.695 | 0.637 |
| Tool-Hang-PH | 1.000 | 0.806 | 0.807 |
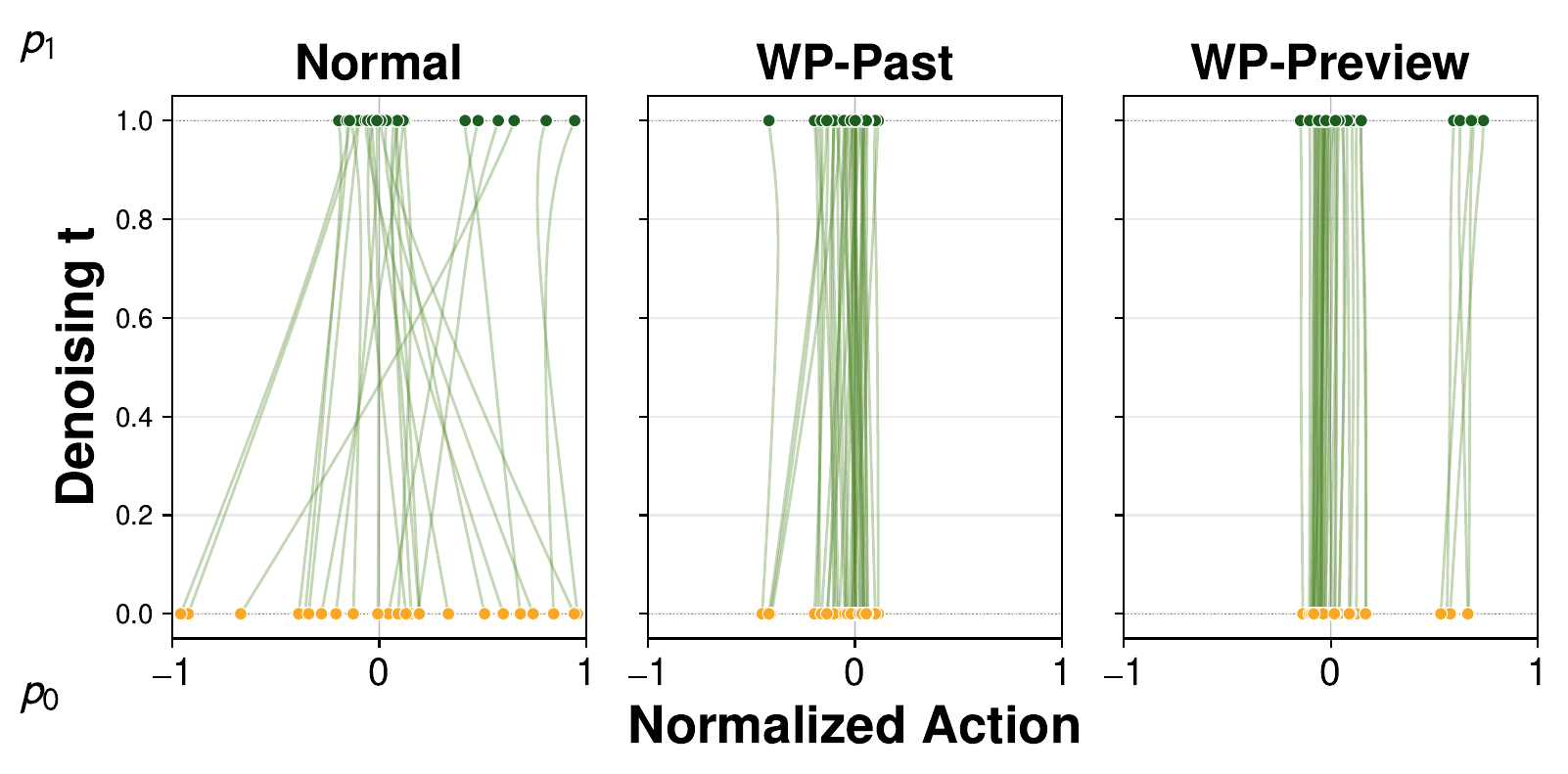
Tasks with the largest curvature reduction (Square-MH, Transport-MH) also show the largest success-rate gain.
Flow paths on Square-MH. Normalized action coordinate vs. denoising time \(t \in [0, 1]\). WarmPrior paths are straighter and more parallel than the baseline.
We make this quantitative through a branching cost bound:
A better prior mean \(\mu\) tightens the first term, while the residual \(\sigma^2\) governs the second, and the two interact through a non-trivial trade-off: too small a \(\sigma\) concentrates the source onto \(\mu\) and is fragile when \(\mu\) is imperfect, while too large a \(\sigma\) leaves the field less tightly straightened. See Appendix B of the paper for the full derivation.
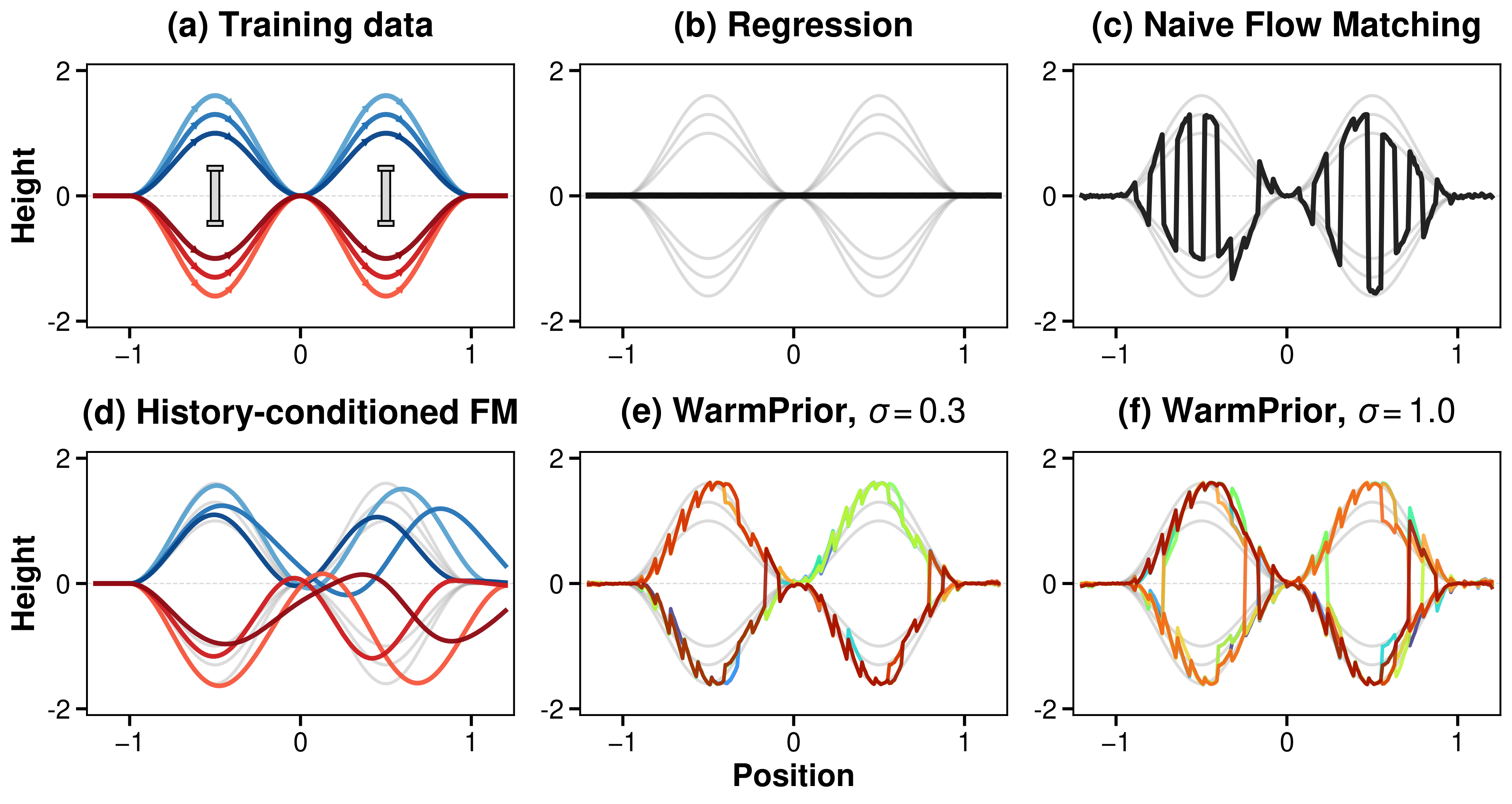
Setup. A 1D navigation toy where the observation \(o\) is the agent's horizontal position and the action is its vertical height. Demonstrations split evenly between passing above and below each obstacle, so the conditional \(p(a \mid o)\) is multimodal at every position. A regression policy collapses to the mean and drives straight through the obstacle (panel b).
Mode switching. A flow-matching policy recovers both modes per inference (panel c), but the standard objective places no constraint linking consecutive chunks: at every chunk boundary the policy can flip between modes. We call this pathology mode switching. Action chunking commits within a chunk but does not stop the oscillation. Naive history conditioning (panel d) eliminates the flips only by pinning each rollout to a single mode, sacrificing multimodality, and is further fragile to inference-time distributional shift over the action history.
σ as a knob. Because the WarmPrior mean is correlated with the previous chunk, a small \(\sigma\) keeps the new chunk in the nearby mode's basin and prevents crossings between distant modes (panel e); a large \(\sigma\) broadens the source and recovers the multimodal distribution at every step (panel f). \(\sigma\) thus becomes a continuous regulator between temporal consistency and multimodal expressiveness, an implicit alternative to history conditioning that does not pin the policy to a single mode.
Four tabletop tasks on a Franka Research 3 using the DROID setup,
with the GR00T N1.5 VLA backbone.
30 demos per task, 50 trials per seed, 3 seeds, NFE = 4.
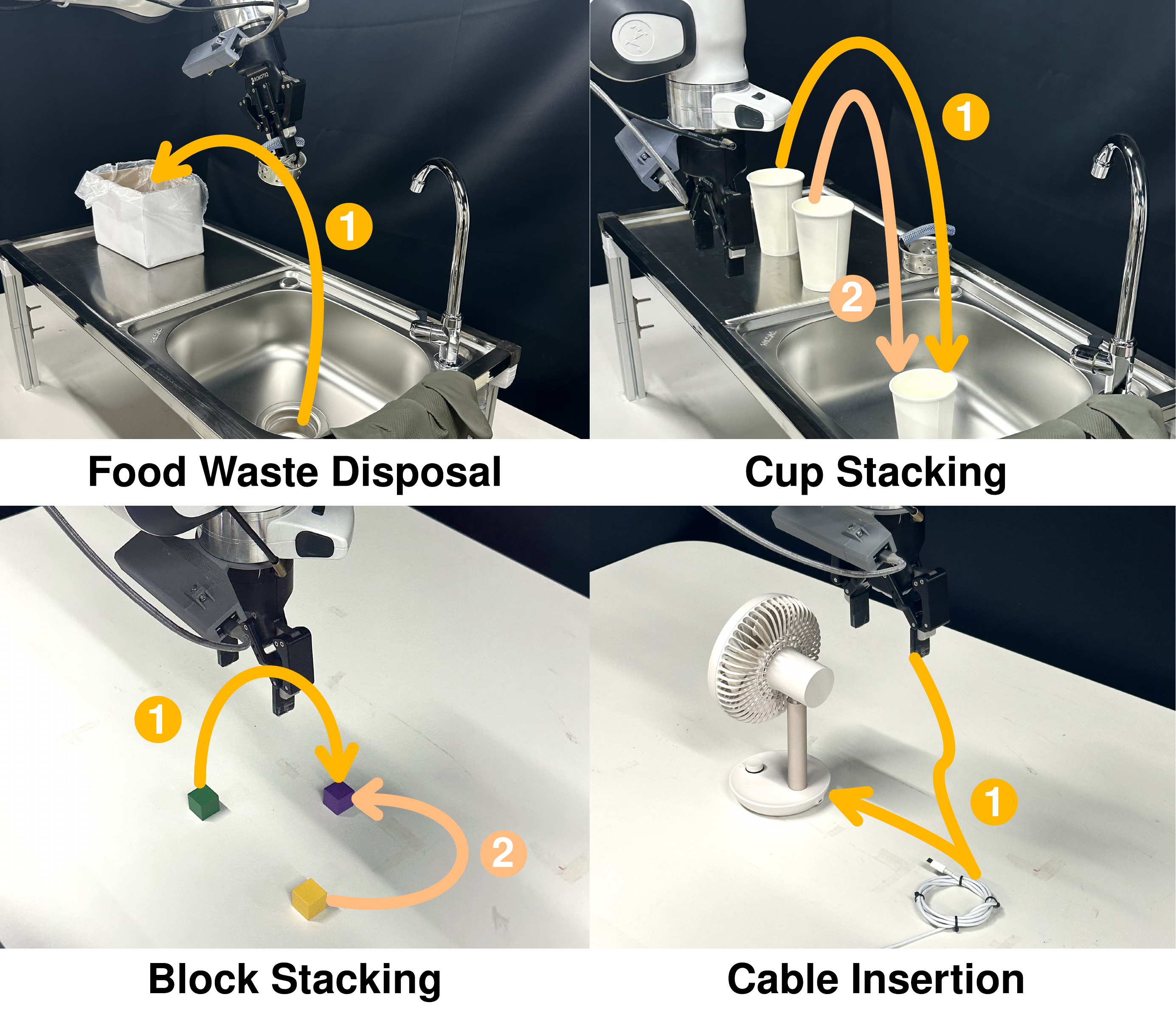
Four tabletop tasks: Food Waste Disposal, Cup Stacking, Block Stacking, Cable Insertion.
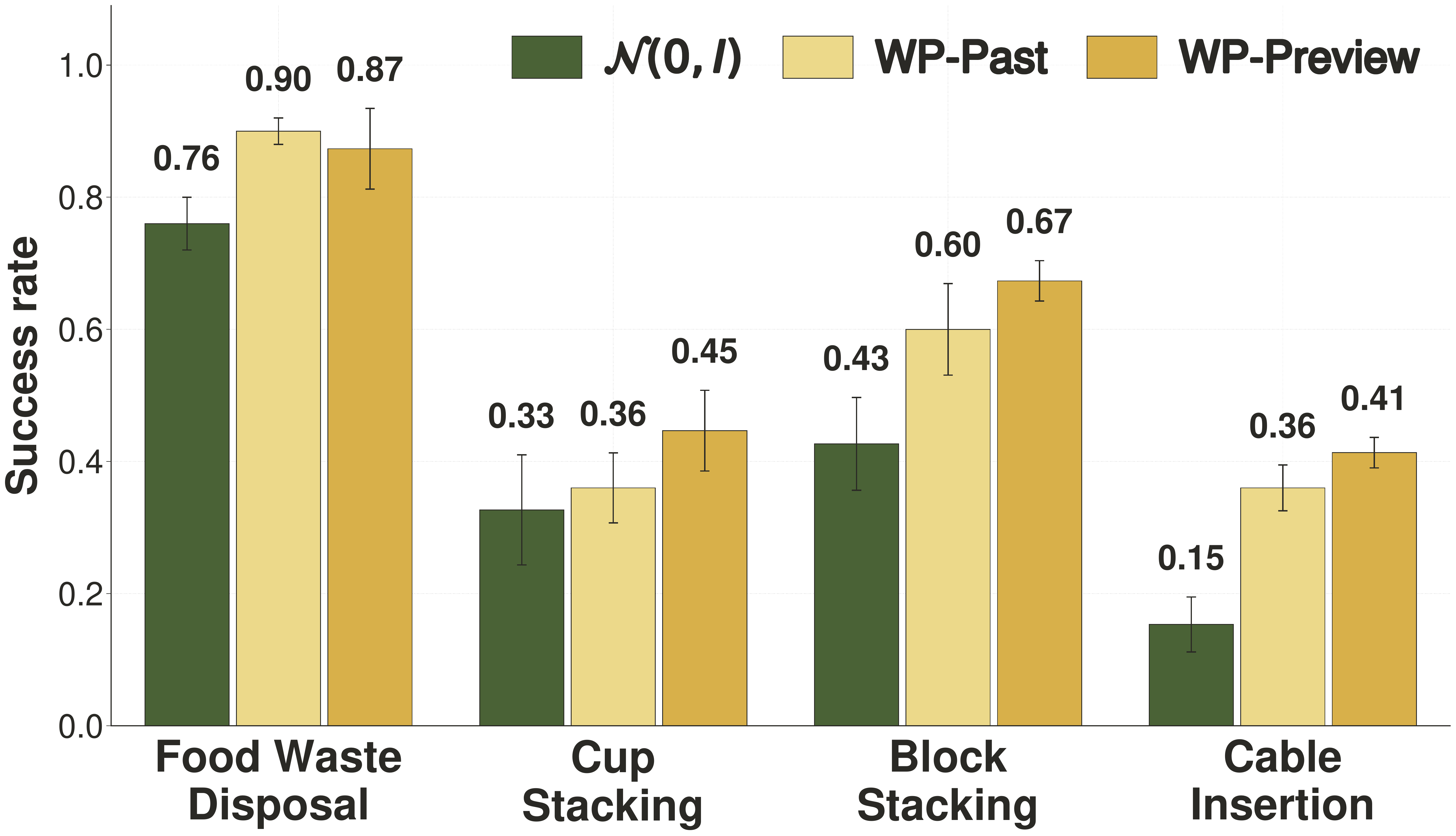
WarmPrior consistently improves success rate. Gains are largest on the harder tasks (Cable Insertion, Block Stacking) where endpoint ambiguity is highest, mirroring the simulation pattern.
DSRL-WP: residual parameterization. We adapt DSRL to the WarmPrior policy by reparameterizing the prior sample as a residual around the WarmPrior mean \(\mu\) and conditioning the RL agent on that mean. The augmented observation is \(\tilde{o} = [o, \mu]\), and the RL policy outputs a bounded offset \(\Delta\) that is added to \(\mu\):
We use \(\delta = 1.5\) on Robomimic Square and \(\delta = 1.0\) on Transport, matching vanilla DSRL. Conditioning \(\Delta\) on \(\mu\) lets it adapt to the current mean anchor and keeps the MDP Markovian. We instantiate DSRL-NA with this residual parameterization and call the resulting setup DSRL-WP.
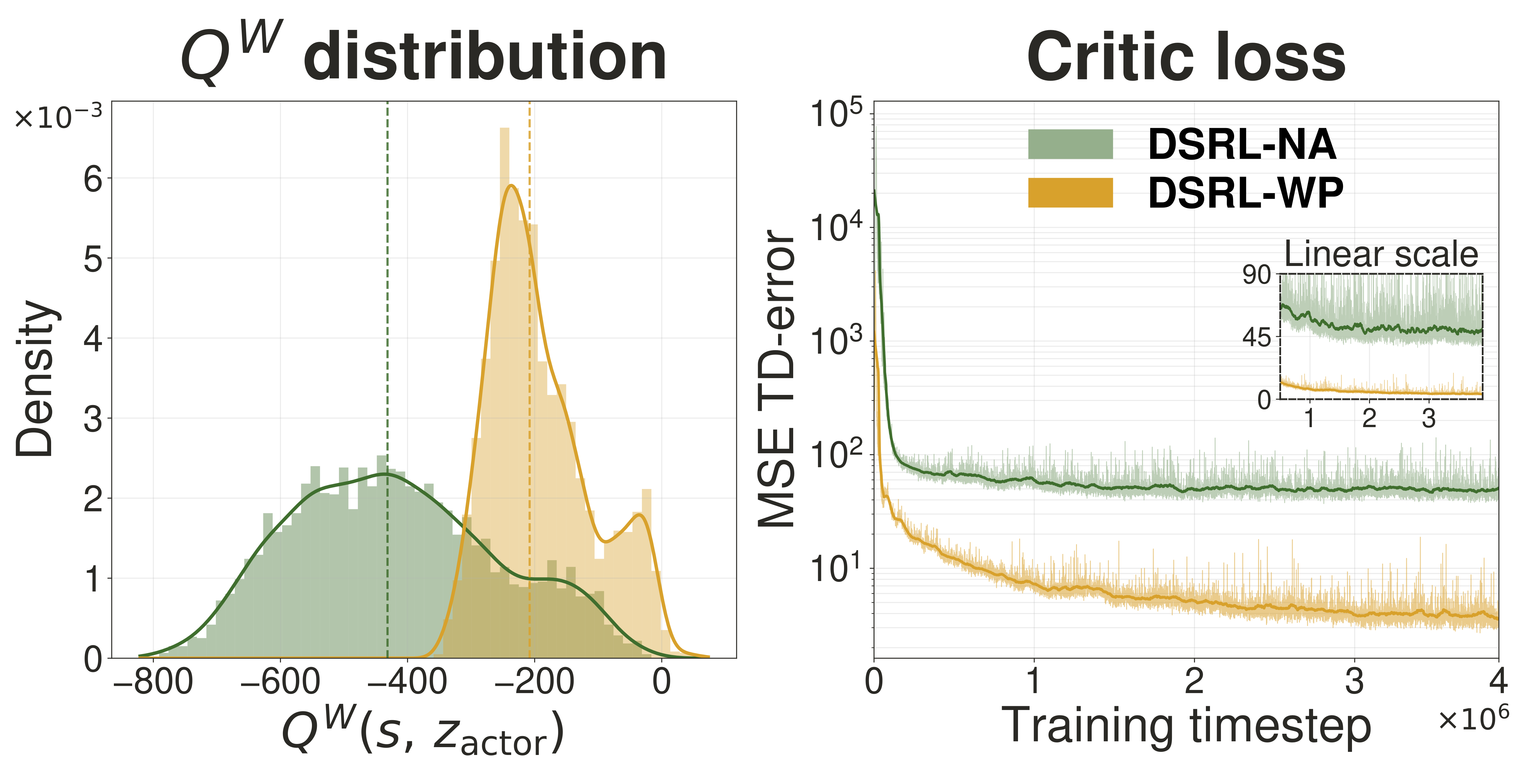
Findings. We fine-tune on Square and Transport, the two Robomimic tasks not saturated under BC, with a frozen WarmPrior backbone pretrained by behavior cloning for 3000 epochs. DSRL-WP learns faster, converges more stably, and reaches a higher asymptote than both DSRL baselines, consistently exceeding 99.0 on Square and attaining 98.1 ± 0.54 on Transport, where DSRL-NA and DSRL-SAC plateau around 90.0. Two further findings on the Transport task accompany this gain. DSRL-WP attains \(Q^W\) values at the actor's deterministic output that are consistently higher than the DSRL-NA baseline. DSRL-WP also achieves a critic MSE TD-error roughly an order of magnitude lower throughout training, with tighter per-step fluctuations. We read both as signs that WarmPrior makes the RL policy search a localized region of the prior space where samples already decode to good actions, rather than the random noise space, consistent with the faster convergence reported above. This action-aligned prior space also yields the stronger asymptotic performance.
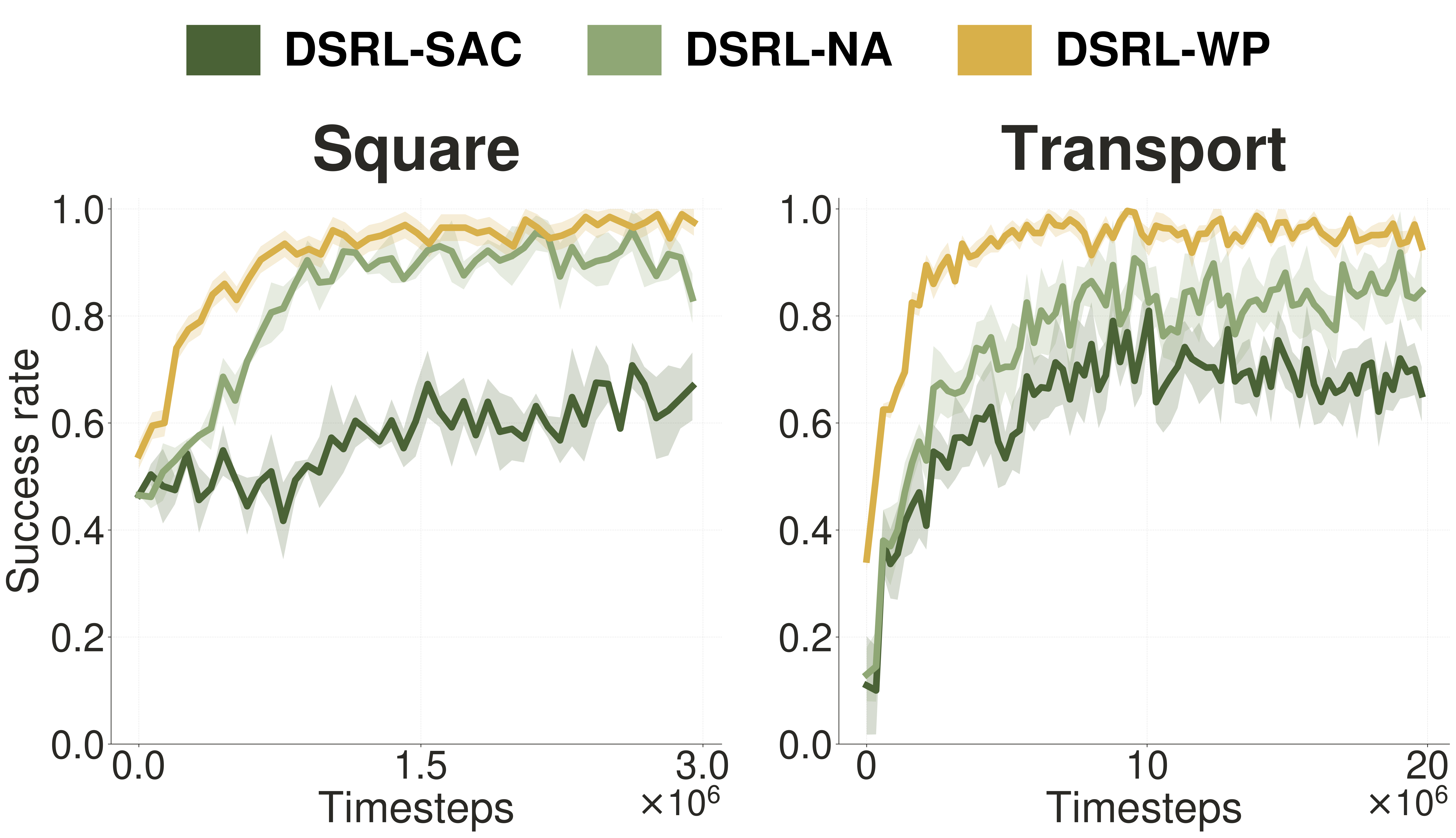
Prior-space RL. DSRL baselines vs. DSRL-WP on Square and Transport, averaged over 3 seeds (±1σ shading).
WarmPrior improves critic learning. DSRL-WP achieves higher \(Q^W(s, z_{\text{actor}})\) across 4k demonstration states (left) and ~10× lower critic loss with smaller fluctuations (right) on Transport.
@article{kang2026warmprior,
title = {WarmPrior: Straightening Flow-Matching Policies with Temporal Priors},
author = {Kang, Sinjae and Kim, Chanyoung and Wang, Kaixin and Zhao, Li and Lee, Kimin},
journal = {arXiv preprint arXiv:2605.13959},
year = {2026}
}